Architecture
Data Validation and Storage
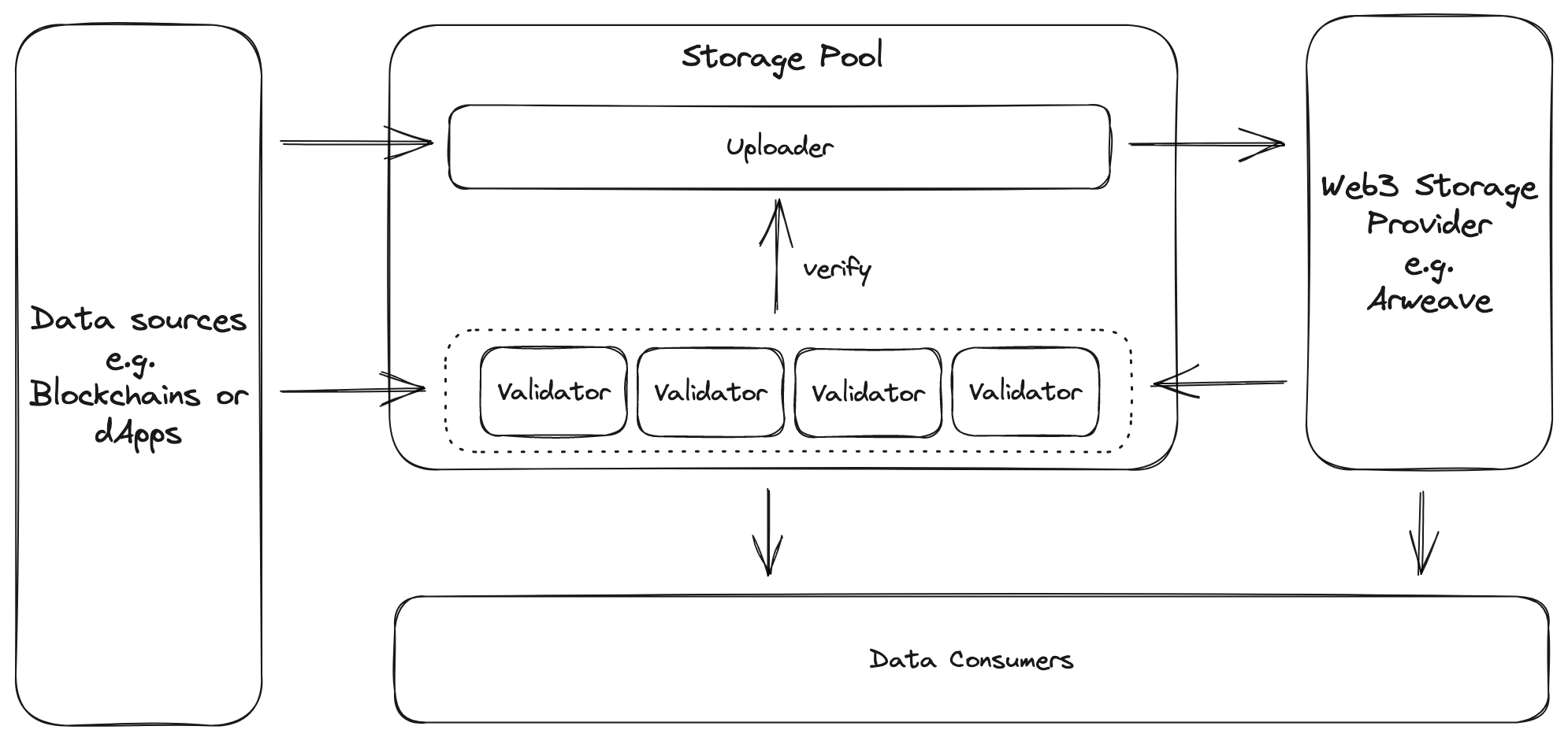
KYVE's objective is to validate and store data streams on decentralized storage providers without the requirement of trust. To accomplish this, KYVE utilizes its Proof of Stake blockchain with a network of data pools which run on top of it. Uploaders collect data from sources, store them on decentralized providers, and submit them to data pools for validation by network participants known as validators. The validated data can then be accessed by data consumers to construct decentralized applications without the need to trust KYVE or any intermediaries.
Layers
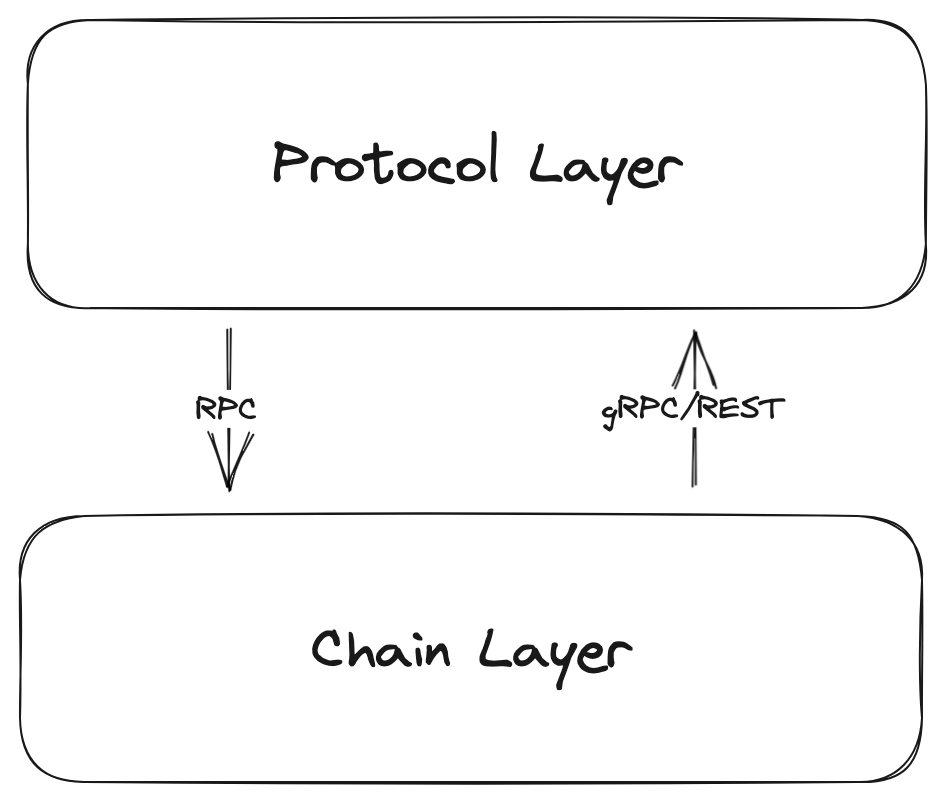
To achieve this at scale, KYVE consists of two layers: the consensus layer and the protocol layer. Here, the consensus layer is a sovereign Proof of Stake blockchain built with Cosmos and using the Tendermint consensus engine. Its main goal is to find consensus and secure the protocol layer on top of it. The protocol layer has all the logic which makes KYVE unique and enables the actual data validation.
Nodes
Since there are two different layers, each essential but with very different requirements, KYVE also has two different types of nodes. First we have the consensus validators which are a set of validators that are responsible for committing new blocks in the blockchain. These validators participate in the consensus protocol by broadcasting votes which contain cryptographic signatures signed by each validator's private key.
Then there are protocol validators which always run on a specific data pool and are responsible for validating and archiving a specific data source. Protocol validators collect data from the data source, submit them to a data pool where other pool participants can validate the submitted data on their end. Every participant is able to cast a vote on the validity of the data. Depending on the result of the votes, the data will be archived and the participant that uploaded the data will receive a reward for their efforts.
A more detailed overview and guides on how to run those nodes can be found here
The diagram below shows the different types of nodes and where they are actually running:
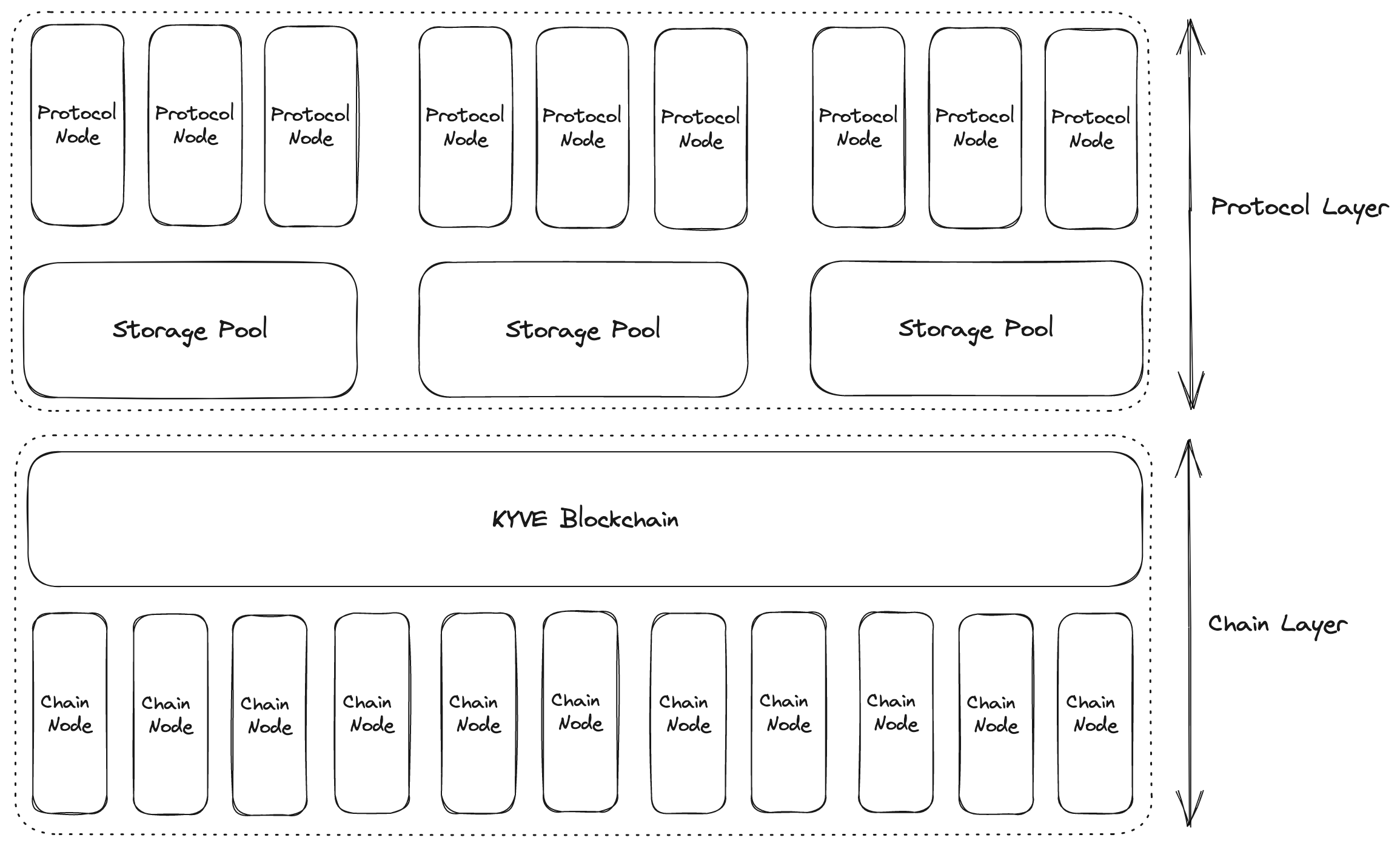
As already mentioned above, protocol validators are responsible for the actual data validation, while the consensus validators are responsible for finding consensus and securing the network. The submission of data, the voting and the vote tallying at the end is all implemented directly into the blockchain itself with the help of Cosmos SDK modules.
You can find all the info about how the KYVE protocol works in detail here